

Rückverfolgbarkeit und digitale Assistenzsysteme sind in der modernen Produktion unverzichtbar. Sie ermöglichen die Erfassung qualitätsrelevanter Informationen über den gesamten Produktionsprozess hinweg und helfen, komplexe Fertigungsprozesse zu bewältigen. Die Integration verschiedener Datenquellen ist entscheidend für tiefere Einblicke in Prozesse, Anlagen und Qualität, wird jedoch durch unterschiedliche Datenformate, Kodierungen und Softwareschnittstellen erschwert.
In unserem neuesten Blogbeitrag stellen wir die LinkedFactory-Datenarchitektur vor und wie diese Ihnen bei der Erfassung, Verwaltung und Abfrage relevanter Produkt- und Prozessdaten behilflich ist, indem sie nahtlos Ihre bestehenden IT-Infrastruktursysteme ergänzt, ohne diese ersetzen zu müssen.
Was steckt hinter dem LinkedFactory-Ansatz und für was kann dieser verwendet werden?
LinkedFactory (LF) ist ein Datenarchitekturkonzept zur Strukturierung von Zeitreihendaten unter Verwendung semantischer Beschreibungen von Ressourcen, um vernetzte digitale Darstellungen von technischen Systemen zu erstellen. Die Kombination von Prozess-, Produkt- und Ressourcendaten ist unerlässlich, um die Einflussfaktoren auf Produktqualität und Produktionsleistung besser zu verstehen. Unternehmen stehen dabei jedoch vor vielfältigen Herausforderungen. Zum einen werden Bezugsobjekte wie Produkte, Prozesse und Ressourcen in unterschiedlichen Strukturen (z. B. Stücklisten, CAx-Daten) und Datentypen (z.B. numerische Werte, Zeichenketten, Datensätze) aus verschiedenen Quellen wie Steuerungssystemen und Sensoren erfasst. Zum anderen erzeugt die Datenerfassung zwar große Mengen an Informationen, diese sind jedoch häufig weder universell verständlich aufbereitet noch leicht zugänglich und auswertbar. Während semantische Modelle bei der Organisation der Daten helfen, indem sie Struktur- und Herkunftsinformationen erfassen, sollte eine flexible Datenarchitektur die Integration von beobachteten Objekten und ihren Attributen zu jeder Zeit ermöglichen.
Die LinkedFactory-Architektur definiert dabei ein einfaches Datenformat und Protokoll, um Produktionsdaten zu erfassen, zu speichern und abzurufen. Dadurch wird ein generisches Datenmodell realisiert, welches es ermöglicht Zeitreihendaten und die zugehörigen Metadaten durch Nutzung der Linked-Data-Prinzipien zu speichern und zu verknüpfen. Dies ermöglicht die flexible Abbildung von Daten für mehrere Anwendungsfälle, z.B. in bauteil-, prozess- und maschinenzentrierten Sichten. Sie entstehen durch die gezielte Nutzung von Internet-kompatiblen Bezeichnern, sogenannten URIs, als Werte in Zeitreihen und Ereignisdaten. Somit können die produzierten Bauteile einer Maschine zeitlich aufgezeichnet und als Objekt selbst mit zugehörigen Prozessdaten verknüpft werden.
| Linked Data Prinzipien helfen, Daten im Web so zu organisieren, dass sie leicht auffindbar, zugänglich und miteinander verknüpft sind – genau wie Webseiten im Internet. |
Der web-orientierte Ansatz ermöglicht es, zwei in der Regel heterogene Datensätze miteinander zu verbinden: semantische Beschreibungen komplexer Produktionssysteme auf der einen Seite und hochvolumige und hochfrequente Produktionsdaten auf der anderen Seite (weiterführende Infos unter https://github.com/linkedfactory/specification). Zusammenfassend dient der LinkedFactory-Ansatz zur Überwachung, Analyse und Steuerung von Produktionsprozessen. Dies kann als Basis für datengestützte Services und digitale Zwillinge fungieren und ermöglicht durch die Verfeinerung der Daten informierte Entscheidungen und maschinelles Lernen.
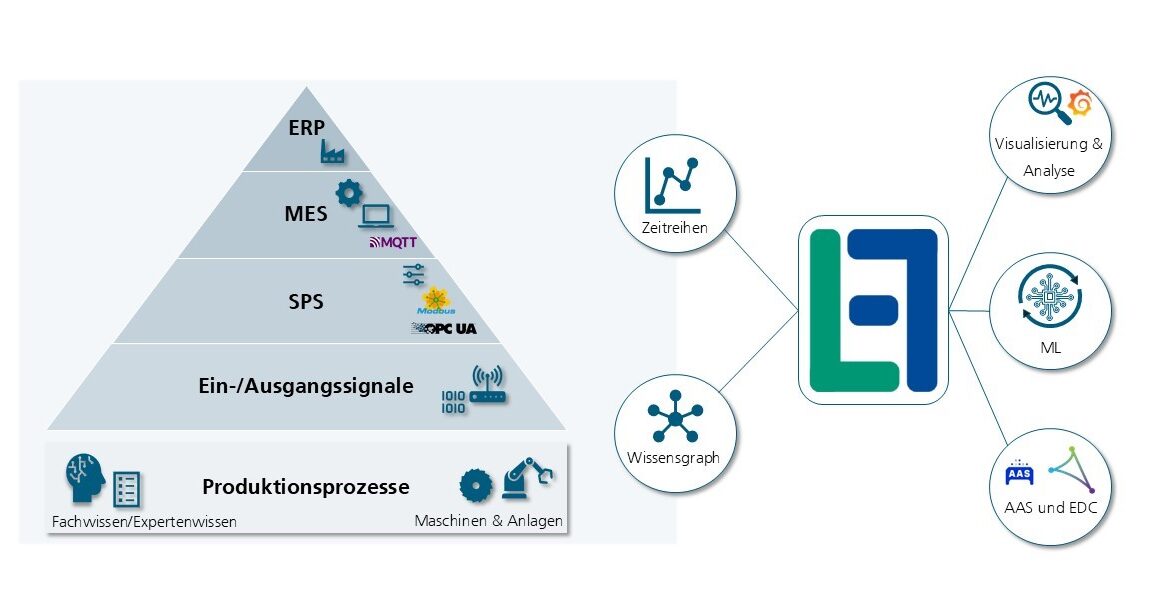
Wie funktioniert die LinkedFactory-Datenarchitektur und welche Industriestandards werden unterstützt?
Die Daten werden typischerweise über maßgeschneiderte Konnektoren gesammelt und in das LF JSON-Format umgewandelt, das über Streaming (wie Kafka oder MQTT) weitergeleitet oder in einem lokalen oder dezentralen historischen Datenservice unter Verwendung der LF HTTP API gespeichert wird. Für gängige Industriestandards wie OPC UA, Modbus oder BACnet werden konfigurierbare Konnektoren bereitgestellt, die die Quelldaten automatisch sammeln und umwandeln. Eine Open-Source-Referenzimplementierung wird als LinkedFactory Pod (weiterführende Informationen unter https://github.com/linkedfactory/linkedfactory-pod) bereitgestellt und implementiert mehrere Speicher-Backends zur Verwaltung von Zeitreihendaten.
| RDF (Resource Description Framework) ist ein Standard, mit dem man Daten im Web so darstellen kann, dass sowohl Menschen als auch Computer sie leicht verstehen und nutzen können. Einfach erklärt ist RDF wie ein System, um Informationen in Form von einfachen Sätzen aufzuschreiben, die aus Subjekt, Prädikat und Objekt bestehen. |
Ein weiteres Kernmerkmal der LF ist die Möglichkeit, RDF-Metadaten für umfangreiche Struktur- und Herkunftsinformationen zu speichern. Auf dieser Grundlage ermöglicht LF die Integration von Zeitreihendaten aus unterschiedlichen Quellen und erlaubt gleichzeitig maßgeschneiderte RDF-Metamodelle für verschiedene Anwendungsfälle. Innerhalb dieses flexiblen Ansatzes ist es möglich, verschiedene Arten von semantischen Beschreibungen zu nutzen, unabhängig davon, ob sie auf Ontologien basieren, einfache RDF-Beschreibungen verwenden oder aus anderen Modellierungsansätzen, wie dem Semantic Aspect Meta Model (SAMM) stammen. Darüber hinaus können auch Standards, wie die Verwaltungsschale (AAS) eingebunden werden. Damit zahlt das LinkedFactory-Konzept auf die Ziele der Industrie 4.0-Initiativen GAIA-X, Catena-X und Manufacturing-X ein.
| Metadaten sind Daten über Daten – sie beschreiben und kontextualisieren andere Daten, z.B. deren Herkunft, Struktur oder Zweck. Zeitreihendaten hingegen stellen Werte über einen zeitlichen Verlauf hinweg dar, wie zum Beispiel Temperatur- oder Kraftmessungen. Metadaten, wie die Prozessreihenfolge oder die Maschinenstruktur müssen in beliebige Richtungen navigierbar sein, während Zeitreihendaten, wie die Zerspankraft auf ein Werkzeug zeitlich durchsuchbar sein sollten. |
Da in den meisten Produktionsumgebungen verschiedene Datenquellen eine Rolle spielen, ist es wichtig, die Daten aus mehreren unterschiedlichen Quellen gleichzeitig abrufen und zu einem einheitlichen Ergebnis kombinieren zu können, ohne die Daten zuerst an einem Ort zusammenführen zu müssen (föderierte Abfragen). Zu diesem Zweck wird die Abfragesprache SPARQL verwendet. Sie kann genutzt werden, um DataFrame für ML-Training zusammenzustellen, benutzerdefinierte Analysen durchzuführen und Visualisierungen zu erstellen (z. B. mit Grafana).
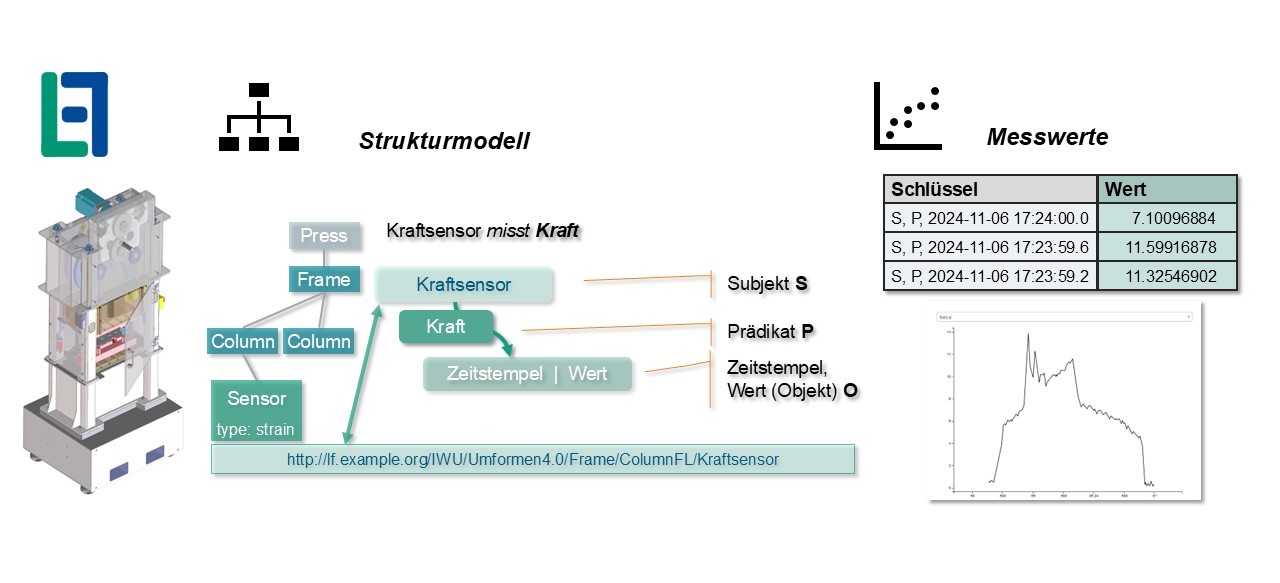
Das in der vorhergehenden Abbildung gezeigte Beispiel betrachtet eine Presse, die wir zur Demonstration der Datenerfassung verwenden. Die Presse besteht aus einem Rahmen, Säulen und weiteren Komponenten, die in einem RDF-Modell erfasst werden. In den Säulen sind Dehnungsmesstreifen verbaut, um die Kräfte während eines Hubs zu messen. Im zeitlichen Verlauf ergibt sich eine typische, auf der rechten Seite dargestellte Kurve. Um diese Zeitreihe effizient zu speichern bilden wir aus der URI des Sensors zusammen mit einer frei wählbaren Eigenschaft – in diesem Fall Kraft – und dem Zeitpunkt der Erfassung ein Tupel, das als eindeutiger Schlüssel für den Wert verwendet wird. Basierend auf dieser Vorgehensweise können die Daten sehr effizient in Key-Value-Stores, SQL-Datenbanken oder spezialisierten Zeitreihendatenbanken gespeichert und abgefragt werden. Durch die Verwendung von SPARQL ist die Auswertung der Daten sehr einfach und kann sowohl in spezialisierten Anwendungen als auch in Tools wie Grafana erfolgen.
Interessieren Sie sich für die LinkedFactory und deren Vorteile für Ihre Produktionsprozesse?
Wir helfen Ihnen gerne weiter! Ob Sie Fragen haben oder maßgeschneiderte Lösungen suchen, die perfekt auf Ihre Anforderungen abgestimmt sind – wir sind für Sie da. Kontaktieren Sie uns für eine persönliche Beratung oder um mehr über die Integration der LinkedFactory-Datenarchitektur in Ihre bestehende IT-Struktur zu erfahren – wir freuen uns auf Ihre Nachricht!



